Technical Debt: The Silent Killer of Your Productivity
I chose not to refactor and improve the project immediately but keep adding more features using the existing crumbling code base…

A couple of years ago, i jumped ship to a well known outsource company in my country, i was really happy at the time because not only my salary raised but it’s an opportunity to learn new thing from new people.
I joined a legacy project which has been through many generations of developers and companies and i gotta say, it’s quite bloated.
I chose not to refactor and improve the project immediately but keep adding more features using the existing crumbling code base to save time. Till one day… it collapsed and took away my time and the trust of my clients.
Here are top signs you need to spend less time adding more features and more time refactoring & improving the code base or it will send you into space.
No centralized logic
The project was structured in a layer fashion. In theory, each layer is responsible for one thing but i found the business logic spans multiple layers (or even in multiple repositories). It results in changing multiple places just to get one simple job done. If you have to modify your code in multiple repositories, it will consumes more time because you have to spend time setting up local environment to test thing locally and wait for CI CD to run in multiple repositories.
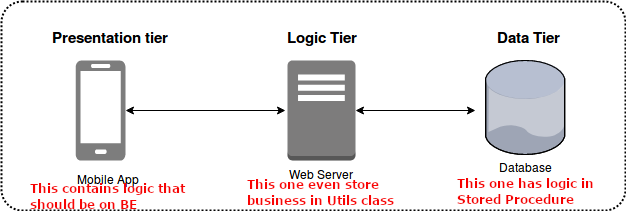
This one is easy to see but hard to improve because we usually have to change a huge amount of code. For example, moving validation logic from front end to backend requires us to invent a way to load it dynamically in Front end, it also requires time and effort of the whole team. Usually, people just keep going with it till there is a requirement for building an additional UI like mobile app.
Refer Shotgun Surgery codesmell.
Code that cannot express intention
Poorly modeled code
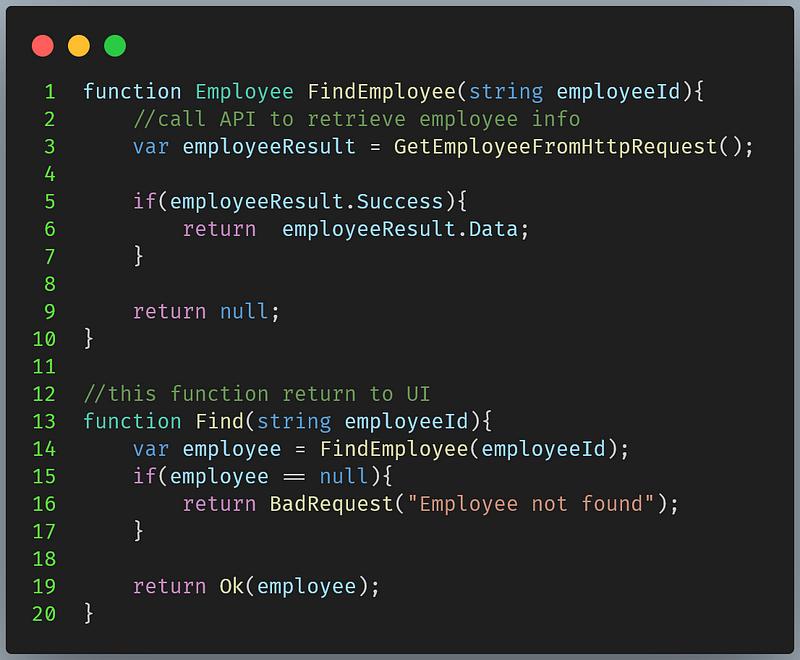
The above code made an assumption that when employee is NULL, the employee is not found. Because the FindEmployee was poorly modeled, it leaves us no choice but to return a generic message for the consumer, we cannot know exactly if the employee was not found or the api which we sent the request was not available at the moment.
Instead, we can model it by using a wrapper type like below
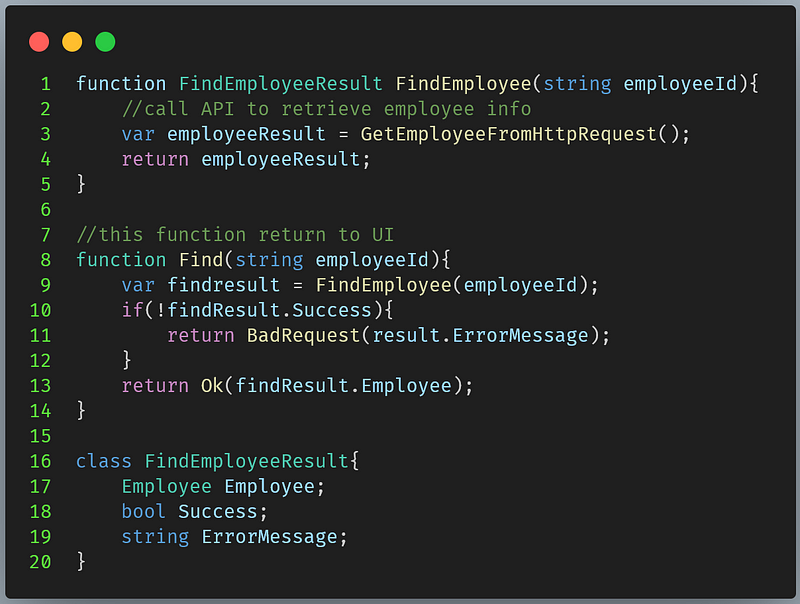
FindEmployeeResultNow we have insightful error message. It’s not only friendly but easier to debug
Try and catch exception
There is nothing wrong with the duo try/catch exception. Using try/catch to handle error and exception could be very handy, but have you ever fall into the try/catch hell? It’s basically just same as callback hell in javascript but your catch could throw exception so you just try/catch again in your catch.
It doesn’t have to be that way, most of our logic could be handle by using wrapper type like in the above section or by using tuple/compose types.
Let’s look at the TryGetValue of Dictionary type in c#.

This method returns false when the key is not found instead of throwing exception.
When to throw exception, then?
When you cannot continue and there’s no way to recover or continue
For example, when your web app start and the setting file is missing, in this case the app choose to throw exception and terminate because there is no way it could recover from that unless the setting file exist and the app is restart again.
Be cautious when using exception, in some cases it could terminate your whole app if not handled properly.
Primitive obsession
Using string type as phone number or email is a poor way to model your logic.
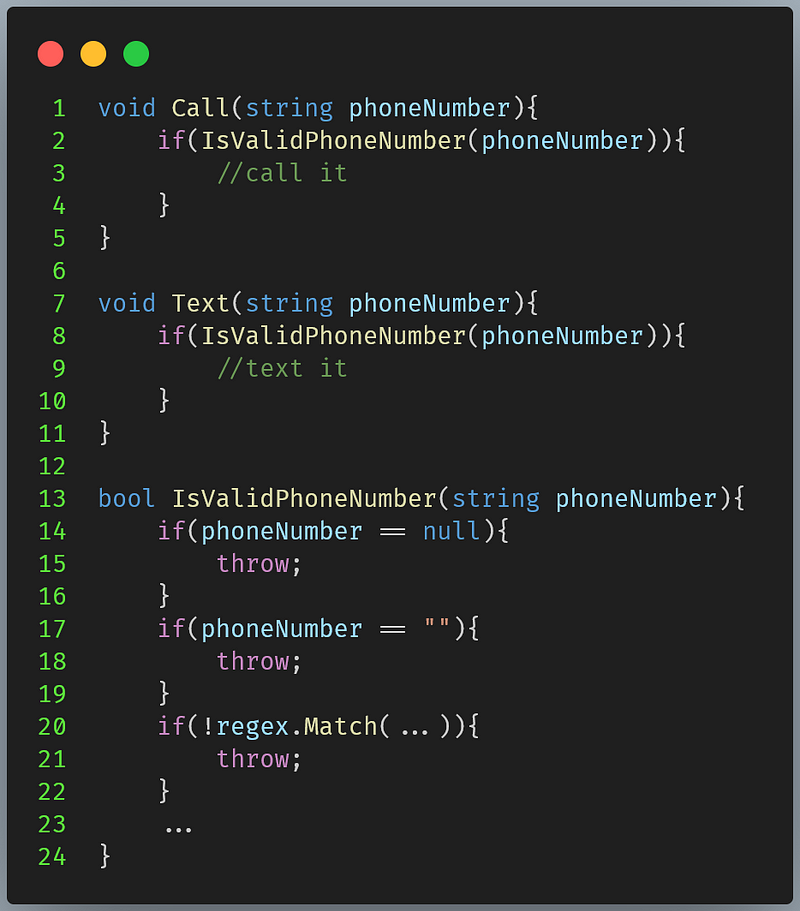
We extract the logic of validating phone number into a separate function but the code keeps duplicating as we checking for its validity, it could even explode if we forget to check it first.
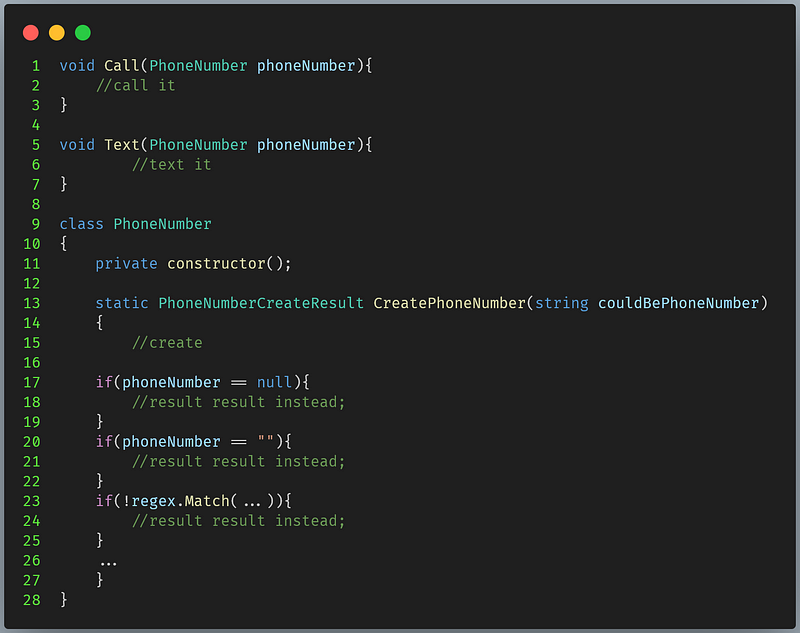
By modeling PhoneNumber by using a class, we don’t have to check for its validity in other methods.
Side effect
Ever change only 1 line of code and commit it with confidence? Or ever change 1 line of code in 1 minute but it takes more than 1 hour to test it because you have to run all the consumers of that API?
We usually mutate input parameter, what if the caller keep using that object after the calling the function?
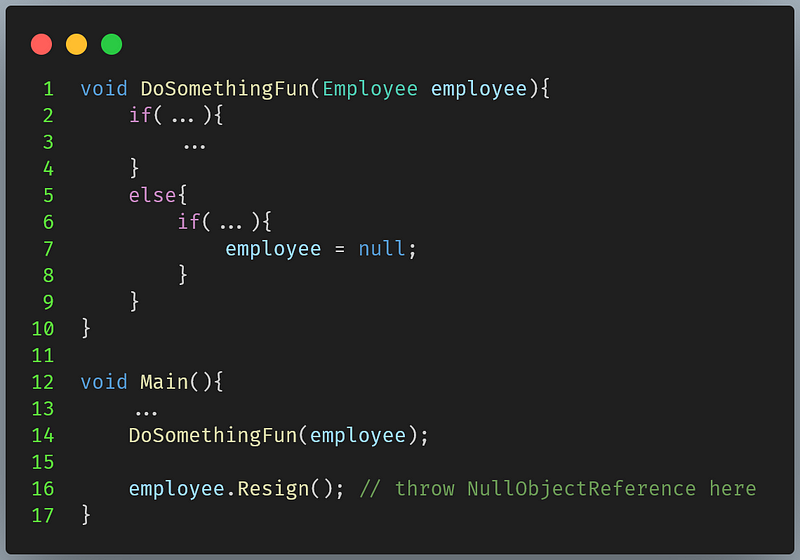
I have described this in another post.

We need to stop mutating everywhere
And more
No Logging and monitoring
This is my face when i look at the database and asking myself “How did it get here?” because there was no logging mechanism implemented.

There was no logging, everything goes into the void. If it works, it’s fine. If it fails, you cannot find the reason immediately but trying to reproduce the problem by querying the data, asking the clients and do educated guess.
With no health check available, we also had no mechanism to receive alert email when our service is down.
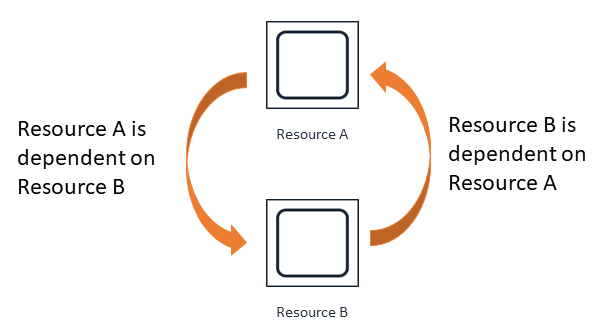
Circular dependencies
I found that many novice developer usually falls into this one. 9 out of 10 times the root cause is that the code relating to infrastructure is not splitted into a separate service or the code doesn’t take Single Responsibility principle seriously.
No database ownership
This is one is common when we developers want to take shortcut and avoid HTTP request between services so they just share the database between 2 or more servers. The advantages is clear, no latency because you don’t need to communicate to the other service to get the data. However, this is a painful experience when many services write data to the same table, how do you know where did the data come from? Moreover, adding more stuff to the database just to find that we need to update the schema in multiple places as well.
And there could be many more
There could be more problems in your code, you could decide to fix it later or just leave it because it works fine.
Overall, we just want to find a way that when we change something, it should change what we intended to.

If you find the post useful, please consider buying me a coffee.