[Rust] —Web Crawling Like A Boss With Reqwest-rs and Tl-rs
Behold the duo Request-rs & Tl-rs. Asynchronous support by tokio-rs makes it even better
![[Rust] —Web Crawling Like A Boss With Reqwest-rs and Tl-rs](/content/images/size/w2000/2025/03/1-gyrwqr7kbticssrfhwyfqw-jpeg.jpg)
Important Notice: Respect Copyright and Ethical Guidelines — This Tutorial is Intended Solely for Educational Purposes!
Introduction
I reside in Vietnam, where English is not our native language. Recently, I developed an application using Rust and Tauri-rs (you can find more information about it here).
The key functionalities of the application revolve around storing the 3000 most frequently used English words along with their corresponding Vietnamese translations. Additionally, the app sends periodic notifications every 30 seconds to introduce a new word, allowing users to learn passively. This approach is akin to encountering advertisements on the street that stick with you, even without actively seeking them out.
The primary challenge I encountered was the absence of Vietnamese translations for the required English words. Manually typing or copying each word proved to be a tedious and time-consuming task. Being a developer, my inclination was towards automating the process, leveraging the power of Rust to streamline the workflow.
The libraries
Tl-rs
According to my Google research, tl-rs is highly regarded as a reliable HTML parsing library. they also prove it themself by providing the benchmark on their site.
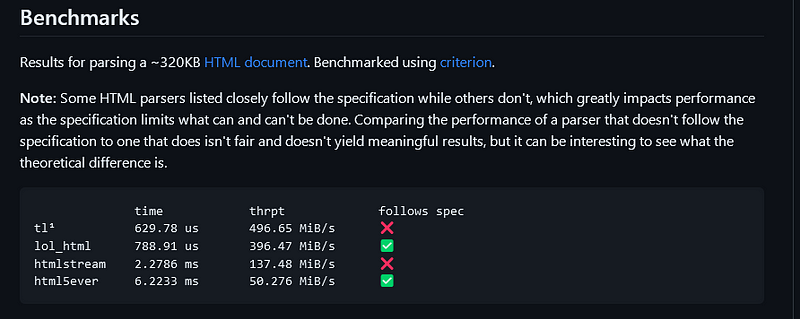
Reqwest
This HttpClient is highly popular in the Rust community due to its friendly API, excellent documentation, and robust async support..
Creating the project
To begin, let’s take a high-level look at the project’s structure and the primary workflow.
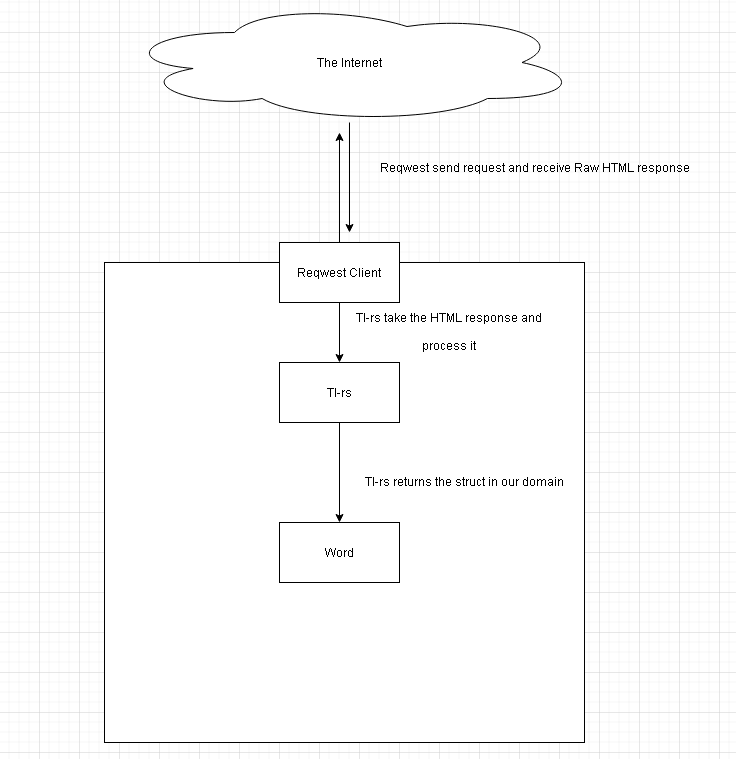
This is also the lifetime of our HTTP request.
Create the project
cargo new --bin crawlerAdd the dependencies
Please note that reqwest relies on tokio-rs as a dependency. Therefore, in order to execute asynchronous code from the main method, we need to include tokio as a dependency in our project. Anyhow serves as a convenient unified error handling mechanism for Result types in our project. We don’t want to explicitly map all the errors from the dependencies to the errors specific to our application. Instead, we can focus on handling the business logic without getting overwhelmed by the intricacies of error propagation.
The code
I will share the essential code snippets and provide detailed explanations for each of them. For further reference, you can find the complete repository at the end of this post.
Main method
Firstly, our objective is to create an HTTP client that can be reused for all requests. The reqwest project offers a convenient and well-documented sample code for demonstration purposes. However, it is important to note that they recommend creating and persisting the HTTP client to leverage the benefits of connection pooling.
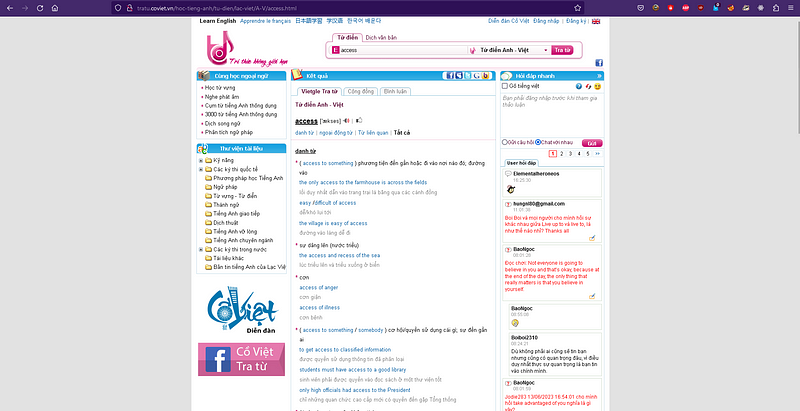
Here’s the website we’re gonna crawl
We will modify our code in the main method, perform the get request and print out the raw HTML.
The result is massive, but we only need a small fraction of it.
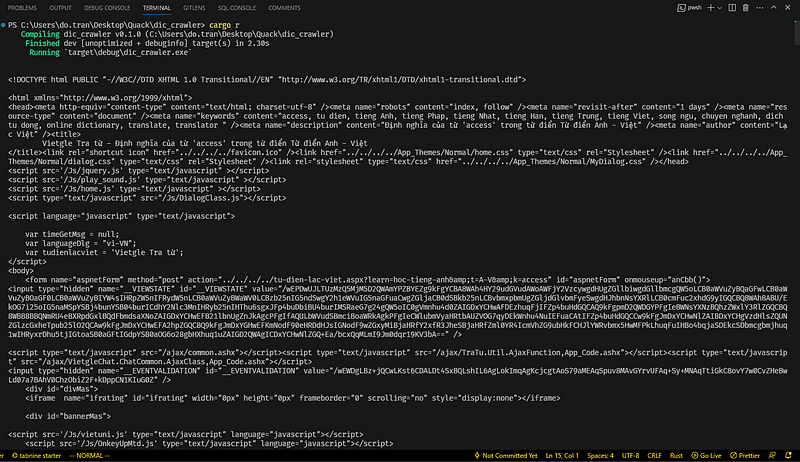
This is where Tl-rs truly excels. With its robust built-in query functions, it offers a seamless experience for parsing and filtering tags within an HTML document, providing ergonomic features for efficient data extraction.
For instance, if we aim to extract the pronunciation of the word “access” as “[‘ækses]”, we can accomplish this by performing a query to retrieve the div element that contains the classes “p5l fl cB”.
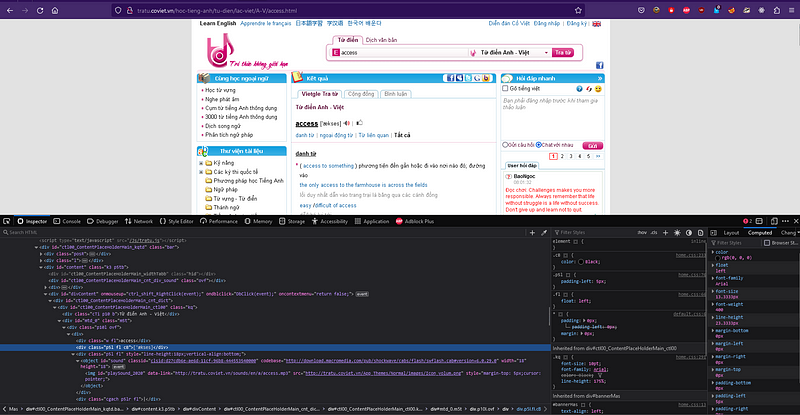
We have made changes to the main function and introduced two additional functions.
In the main function, we utilize the get_dom function to create a VDom object from the raw HTML obtained through reqwest. Subsequently, we delegate the tasks of parsing and extracting the inner text within the div to the extract_pronunciation function.
The get_dom function is a simple and straightforward implementation. It accepts the raw HTML as input and returns the corresponding VDom object. It’s important to note that the lifetime of the VDom is tied to the lifetime of our HTML string, as the tl::parse function takes a reference to the String and does not consume it.
The extract_pronunciation function is slightly more intricate. It receives the VDom object and the query_selector value, attempting to retrieve the inner text of the targeted div. If the query does not find a match, it will fallback to returning None. The process begins with performing the query, and if it yields a result, we iterate through each node and extract the inner text using the inner_text() function.
After making the adjustments to our code, executing the above piece of code would produce the output Some(“[‘ækses]”) on the console.
From this point onward, we have completed all the necessary tasks to extract the data from the HTML document and integrate it into our domain
Conclusion
Processing and extracting HTML can be both challenging and enjoyable to work with. Tl-rs and Reqwest have done an excellent job of abstracting away the complexities and providing us with a user-friendly API. The added support for asynchronous operations is a valuable bonus that enhances the overall experience
If you enjoyed the article, feel free to show your appreciation by giving it a clap and following me for updates on future posts. The source code of the project is published on Github here.