Dissect HTTP Connection: Keep-Alive
As a web developer, you’ve likely encountered the Connection: Keep-Alive header countless times throughout your career. This header offers…

As a web developer, you’ve likely encountered the Connection: Keep-Alive header countless times throughout your career. This header offers a significant performance boost for your server by maintaining open TCP connections for a predefined duration. But how exactly does it function under the hood? Let's delve into the mechanics behind it.
What is HTTP Header Connection: Keep-Alive
The HTTP header Connection: Keep-Alive signals the server from the client to maintain the TCP/IP connection open after responding to a request. This optimization allows subsequent requests within a specific timeframe to reuse the existing connection, eliminating the need for establishing new ones.
The theory
Understand the OSI Model
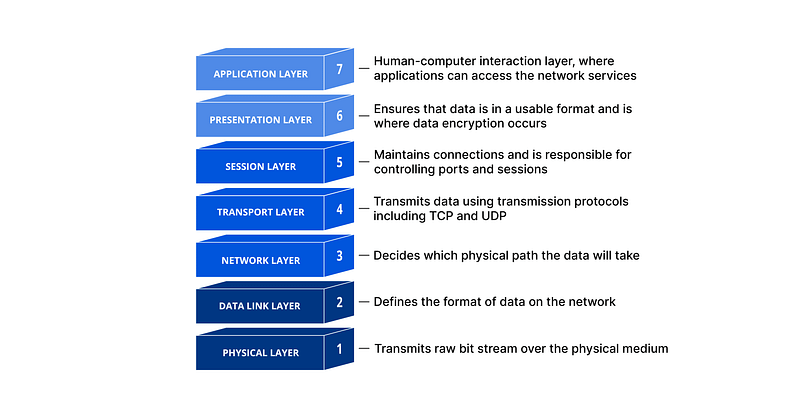
To understand how Connection: Keep-Alive works, let's first explore the Open Systems Interconnection (OSI) model. In simpler terms, the OSI model establishes a common language for various computer systems to communicate seamlessly. (You can read about it here)
Building on the OSI model, the HTTP protocol operates at layer 7, utilizing a TCP/IP socket at layer 3. In essence, HTTP acts as an application-level interface built upon the network capabilities of TCP/IP sockets. To leverage connection persistence, we need to maintain the open socket between the client and server.
The cost of TCP re-connection
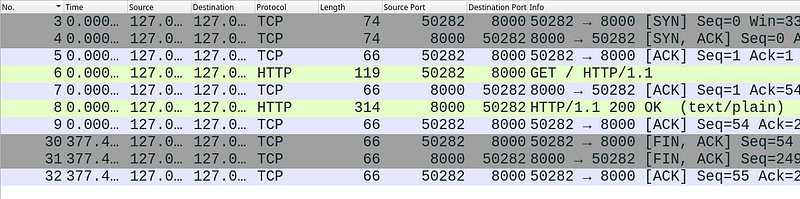
As illustrated in the preceding image, the initial three packets depict the TCP handshake sequence: [SYN], [SYN, ACK], and [ACK]. This crucial exchange establishes the connection before data transmission can begin. While seemingly straightforward, the handshake incurs significant overhead, making its frequent repetition undesirable. We’ll delve into the remaining packets in the image shortly.
The subsequent four lines represent the actual data exchange between the server and client. The client initiates by sending a GET request to the server. The server acknowledges receipt with an [ACK] packet and transmits the requested response. Finally, the client sends another [ACK] to confirm successful reception of the server’s response.
The final three lines depict the TCP connection termination sequence. The client initiates closure by sending a [FIN, ACK] packet. The server acknowledges and reciprocates with its own [FIN, ACK] packet. Finally, the client sends a final [ACK] to confirm successful termination.
HTTP Header “Connection: Keep-Alive”
The Keep-Alive general header allows the sender to hint about how the connection may be used to set a timeout and a maximum amount of requests.The Connection: Keep-Alive header serves as a suggestion, not a mandate. It informs the server of the client's preference to maintain an open connection. Ultimately, the server decides whether to honor this request.
The proof
To illustrate the mechanics of Connection: Keep-Alive in action, we'll leverage two simple Rust programs and the popular network protocol analyzer, Wireshark.
Building on the previous section, we’ll utilize two Rust programs: a “client” and a “server.” The “server” will listen for HTTP requests on port 8000, while the “client” will make HTTP requests to that port. We’ll employ Wireshark to capture and analyze the network traffic exchanged between these two processes
Let’s begin by examining the server code in Rust and providing a concise explanation of its functionality
#[macro_use]
extern crate rocket;
#[get("/")]
fn index() -> &'static str {
"Hello, world!"
}
#[launch]
fn rocket() -> _ {
let fidget = rocket::Config::figment()
.merge(("port", 8000))
.merge(("keep_alive", 30))
.merge(("address", "127.0.0.1"));
rocket::custom(fidget).mount("/", routes![index])
}The server code is relatively simple. It defines an endpoint at the root path (/) that responds with the string "Hello, world!". Within the main function, a server is created to listen on port 8000. Notably, the server configuration includes a keep_alive attribute set to 30 seconds, indicating the server's willingness to maintain open connections for that duration.
#[tokio::main]
async fn main() {
let client = reqwest::Client::new();
loop {
let _ = client
.get("http://localhost:8000/")
.send()
.await
.unwrap()
.text()
.await
.unwrap();
let mut buffer = String::new();
std::io::stdin().read_line(&mut buffer).unwrap();
}
}The client code implements a continuous loop. Each time the user presses Enter, a new HTTP request is sent to the server.
Without the Keep Alive
As previously discussed, the server ultimately decides whether to maintain a persistent connection, regardless of the client’s preference. We included the line merge((“keep_alive”, 30)) in the server code to signal its willingness to keep connections open for 30 seconds. Removing this line disables keep-alive functionality on the server's end. This behavior, where a new TCP handshake occurs for every request, can be observed using Wireshark.
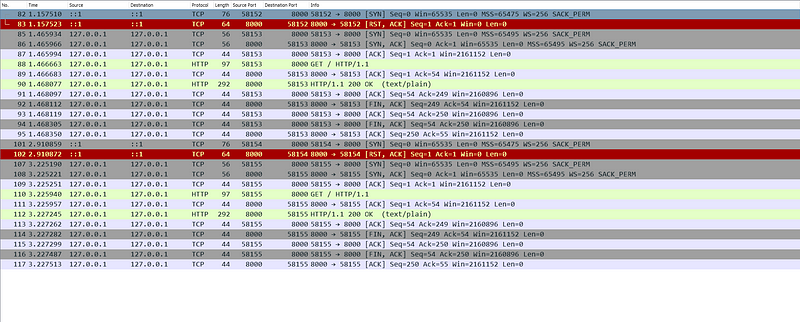
With the Keep Alive Enabled
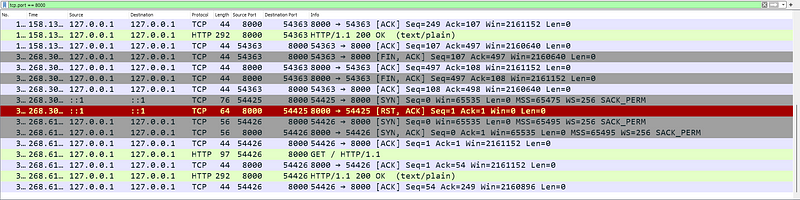
Reintroducing the line merge((“keep-alive”, 30)) back into the server code re-enables its ability to maintain persistent connections. Let's analyze the resulting behavior captured by Wireshark.
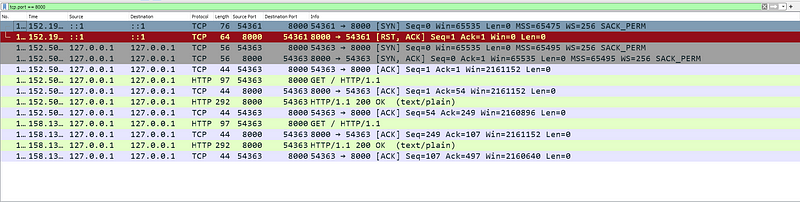
However, if the client doesn’t send a request within the 30-second keep-alive timeout window set by the server, the connection will automatically close. This closure is evident in Wireshark by the exchange of [FIN, ACK] and [ACK] packets before a new HTTP request is initiated, signifying the re-establishment of the TCP connection.
Tuning the Keep Alive Parameter
The keep-alive timeout parameter can be adjusted to optimize performance. However, this value requires careful consideration, as an inappropriately chosen timeout can negatively impact server performance.
- A very low keep-alive timeout can be counterproductive. It might prematurely terminate persistent connections that could still be reused, leading to more frequent connection establishment overhead. This can negatively impact performance.
- Conversely, an excessively high keep-alive timeout can lead to a surplus of open connections. These connections might not even be actively used for new requests. In the worst-case scenario, the server could exhaust resources needed to accept new connections from clients, hindering its ability to handle incoming requests.
Some catch
While persistent connections appear straightforward at first glance, implementation pitfalls can exist. For instance, creating a new client for every request instead of reusing an existing one would negate the benefits of connection persistence. This seemingly minor oversight can significantly erode performance gains.
#[tokio::main]
async fn main() {
//let client = reqwest::Client::new(); //The client was supposed to be here
loop {
let client = reqwest::Client::new();
let _ = client
.get("http://localhost:8000/")
.send()
.await
.unwrap()
.text()
.await
.unwrap();
let mut buffer = String::new();
std::io::stdin().read_line(&mut buffer).unwrap();
}
}It’s important to note that configuration for persistent connections often resides within the web server itself, not necessarily within the application. In cloud environments, due to their inherent complexity, maintaining connections for longer than a few minutes might be impractical. Since cloud resources are shared by multiple applications from various customers, excessively long-lived connections could potentially impact the performance of other applications. Implementing workarounds to address this can be intricate.
Source Code
The source code which used in this post could be found here: